From Local Concepts to Universals: Evaluating the Multicultural Understanding of Vision-Language Models
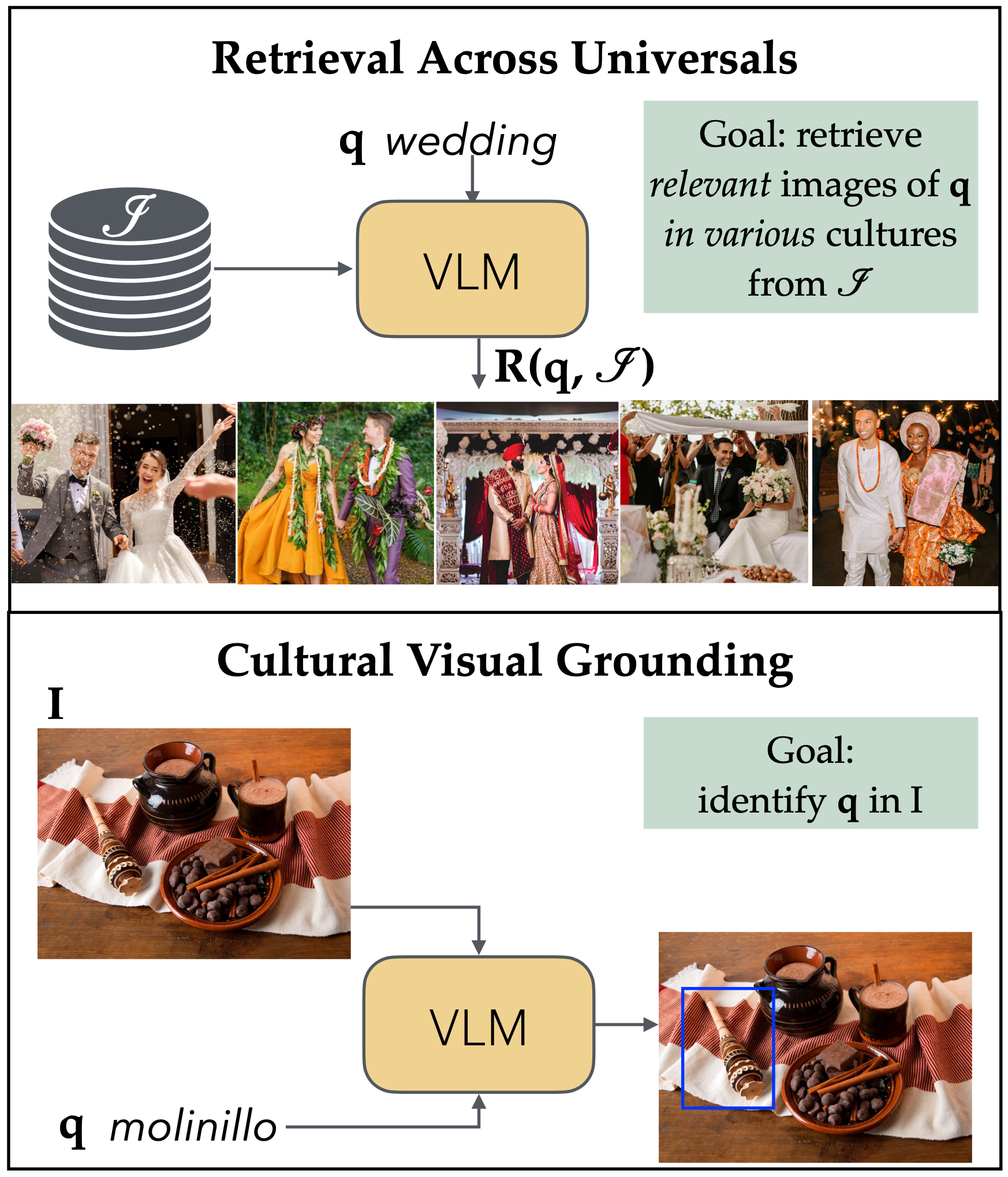
Despite recent advancements in vision-language models, their performance remains suboptimal on images from non-western cultures due to underrepresentation in training datasets. Various benchmarks have been proposed to test models’ cultural inclusivity, but they have limited coverage of cultures and do not adequately assess cultural diversity across universal as well as culture-specific local concepts. To address these limitations, we introduce the GlobalRG benchmark, comprising two challenging tasks: retrieval across universals and cultural visual grounding. The former task entails retrieving culturally diverse images for universal concepts from 50 countries, while the latter aims at grounding culture-specific concepts within images from 15 countries. Our evaluation across a wide range of models reveals that the performance varies significantly across cultures – underscoring the necessity for enhancing multicultural understanding in vision-language models.
ArXiv